- Published on
Apache Spark behind the scenes
- Authors
- Name
- Hung Tran
- @hungtran150


Overview
Có bao giờ bạn thắc mắc, sau khi bạn submit một app vào Spark cluster để thực hiện những tính toán hoặc biến đổi trên dữ liệu, thì Spark sẽ làm gì không?
Bài viết này mình sẽ chia sẻ tổng quan Spark hoạt động như thế nào.
Spark Architecture
Spark Architecture gồm những gì?
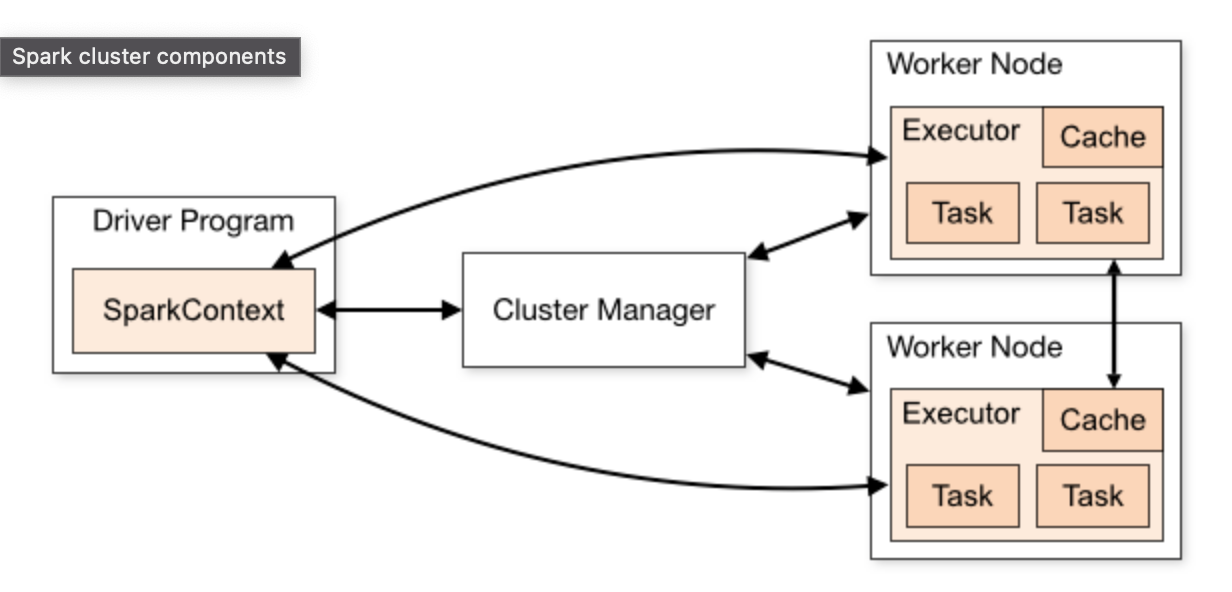
Quan sát hình ta thấy Spark có 3 thành phần chính:
- Cluster Manager
- Driver
- Worker
Thông thường Spark sẽ hoạt động với master node và nhiều worker node, giống với Hadoop master and slave node.
Dưới đây miêu tả chi tiết mỗi thành phần sẽ làm những gì.
Cluster Manager
Cluster manager là một platform mà chúng ta deploy hoặc chạy Spark trên đó lưu ý là chỉ với cluster mode (local mode mình sẽ không đề cập ở đây)
Có những kiểu cluster manager như sau:
- Kubernetes: Hiện tại, Spark ở Fossil được deploy trên Kubernetes (k8s một hệ thống open source dùng để tự động deploy, quản lý, mở rộng cho container)
- Hadoop Yarn: Hệ thống quản lý Big data Hadoop
- Standalone: Đây là kiểu được Spark hỗ trợ để tự dựng 1 cluster cơ bản một cách dễ dàng
- Apache Mesos (Deprecated)
Driver
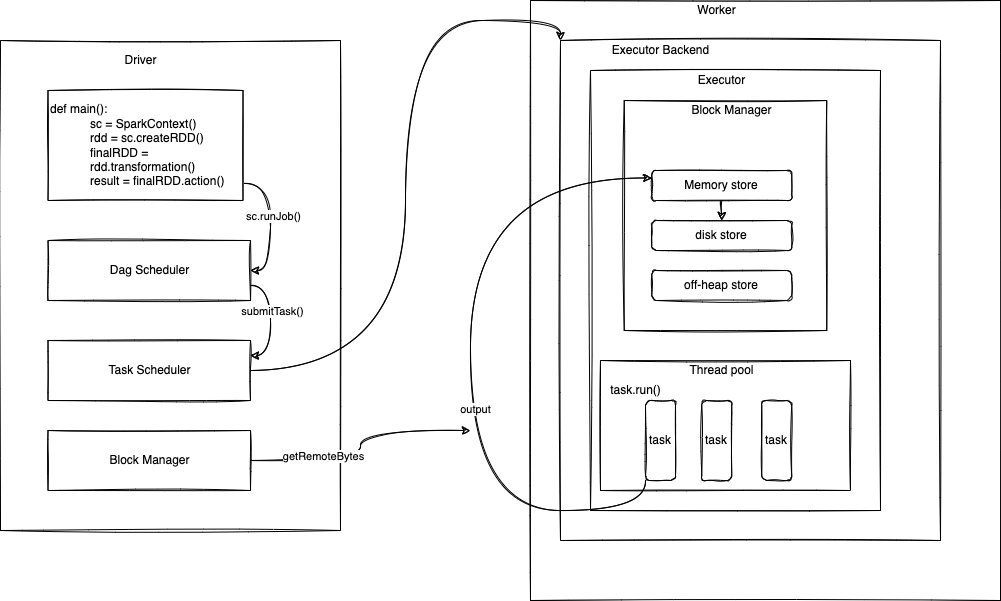
Spark driver là thành phần chính cho những Spark app, nó thường nằm ở master node (Standalone mode, Hadoop Yarn). Tuy nhiên ở Fossil Spark được deploy trên k8s nên mỗi lần client submit một spark app vào k8s cluster, k8s sẽ tạo nên một pod driver cho 1 spark app.
Sau khi Driver được tạo ra, thì nó sẽ chuyển đổi user application thành từng phần nhỏ được gọi là Job và task. Sau đó sẽ chịu trách nhiệm giao tiếp với quản lý tài nguyên để yêu cầu tài nguyên (executor) và phân bổ tài nguyên cho các executor, Driver sẽ quét qua Spark app code để biết được đâu là transformation đâu là action để tạo ra Spark Execution plan (Logical plan và Physical plan). Ngoài việc phân bổ tài nguyên và lên lịch Job cho Executor thực thi, Driver còn làm những nhiệm vụ khác như: Collect status của từng executor, Collect những executor metrics và hiển thị lên Spark UI.
Driver có rất nhiều thành phần.Một số thành phần chính bao gồm:
- SparkContext
- Logical execution plan
- DagScheduler
- TaskScheduler
- BackendScheduler
- BlockManager
Đây là flow xử lý RDD
Còn với DataFrame hoặc SQL hoặc DataSet ta sẽ có 1 flow khác sử dụng Catalyst Optimizer
2 flow chỉ khác nhau ở chỗ Logical plan và physical plan.
- Với RDD Logical Execution plan sẽ không đi qua Catalyst Optimize mà sẽ đi thẳng vào DagScheduler để thực thi.
- Riêng với DataFrame, SQL hoặc DataSet sẽ đi qua Catalyst Optimize trước khi vào DagScheduler.
SparkContext
Spark Context là main entrypoint của tất cả các thành phần trong Spark, thành phần chính của tất cả Spark App.
Logical execution plan
Logical execution plan là 1 abstract của các bước chuyển đổi cần được thực hiện (Có bao nhiêu RDDs sẽ được tạo ra, bởi vì RDD imutable nên mỗi lần transform sẽ tạo ra 1 hoặc nhiều RDD mới tùy vào Narrow hoặc Wide transform) còn được gọi là RDD lineage. Như vậy Logical execution plan được tạo bởi từng transformation của từng RDD và lưu ở SparkContext.
DagScheduler
Sau khi Logical execution plan đã được tạo, khi có 1 action được gọi DagScheduler sẽ chuyển nó thành Physical execution plan (bằng cách sử dụng Job và Stage). Để phân biệt được đâu là method action đâu là method transform mình đã kiếm được 1 slide có những thông tin này cảm ơn vào tác giả có tên là Jeff Thomspon link.
- Job: Mỗi một job là 1 action trong Spark. Action sẽ thực hiện job trên cluster và return value lại cho Spark Driver.
- Stage: Mỗi 1 job sẽ có nhiều stage. Số lượng stage sẽ phụ thuộc vào bạn thực hiện Narrow Transformation hoặc Wide Transformation. Tất cả Narrow Transformation (map, flatmap, …) sẽ được thực hiện trên 1 stage. Khác với Narrow, Wide Transformation sẽ tạo ra 1 stage mới điều này dẫn tới mỗi 1 stage sẽ có stage boundary. Mỗi 1 Stage Spark sẽ lưu data ở local disk.
- Task: Mỗi 1 Stage sẽ có nhiều task, mỗi 1 task sẽ ứng với 1 partition.
Nhiệm vụ của DagScheduler:
- Sẽ tính toán và tạo ra exection DAG (DAG của những stages) cho 1 job sau đó submits những stage đó cho TaskScheduler.
- Xác định preferred locations (Vị trí host, executor id) để run task, ngoài ra nó nó tracking RDD nào đã được cache để không recompute lại.
- Xử lý failures, resumitted nguyên 1 stage nếu có 1 task nào đó bị lỗi.
DagScheduler sử dụng event driven architect, Nếu như có 1 job mới được submit thì DagScheduler sẽ đọc và thực hiện 1 cách tuần tự.
TaskScheduler
TaskScheduler sẽ nhận set of task đã được submit bởi DagScheduler cho từng stage, và có nhiệm vụ schedule và sending task cho worker hoặc executor thực hiện, retry nếu như bị lỗi.
BackendScheduler
BackendScheduler sẽ hỗ trợ nhiều loại cluster manager như: Hadoop-Yarn, Kubernetes, Apache Mesos.
Khi Spark app yêu cầu resource từ cluster manager để thực thi, nếu như BackendScheduler nhận được resource allocate bởi cluster manager, nó có thể start executor.
BlockManager
BlockManager là nơi lưu trữ block of data dưới dạng key-value và chạy trên tất cả các node trong Spark App ví dụ như: Driver, Executor. Nó upload và fetch data block ở local và remote sử dụng nhiều kiểu lưu trữ như: memory, disk, off-heap.
- Nếu như Result trả về quá lớn, nó sẽ được persisted ở “memory + disk” được quản lý bởi BlockManager. Driver sẽ get result thông qua indirectResult (Storage location). Khi nào cần Driver sẽ fetch nó qua HTTP.
- Nếu như Result trả về nhỏ hơn 10mb (
spark.akka.frameSize = 10MB). Nó sẽ được gửi về thẳng driver thông qua directResult.
Catalyst Optimizer
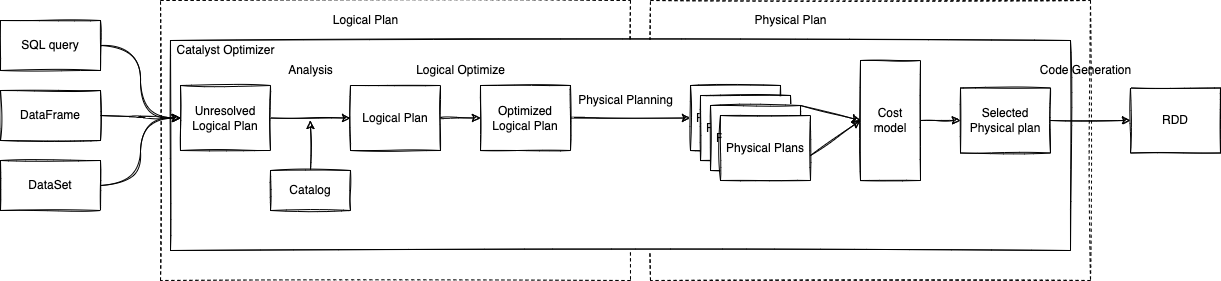
Mình sẽ nói sơ Catalyst Optimizer là gì. Catalyst Optimizer là Core của SQL query và DataFrame, Catalyst Optimizer hỗ trợ Rules-based optimization (Tất cả các Ruled để Optimize và Analysis) và Cost-base optimization (Sử dụng các Rule của Rules-based để optimize dựa vào thống kê và tính toán). Vậy Catalyst sẽ làm như thế nào? Catalyst sử dụng cấu trúc dữ liệu cây để xây dựng query plan hoặc xây dựng cây của những expression, các node của cây được định nghĩa bằng Scala như là subclass của TreeNode class (Ví dụ: 1 node của cây có thể là datatype dạng int, hoặc function add cộng 2 số int). Catalyst sử dụng Rules optimize được định nghĩa sẵn để biến đổi một cây thành 1 cây tối ưu hơn (lát nữa mình sẽ có ví dụ).
Logical Plan
Unresolved Logical Plan
Theo như mình tìm hiểu thì khi code Spark app của chúng ta đúng syntax và valid nhưng tên của các column và các bảng trong query hoặc trong dataframe của các bạn bị sai hoặc không tồn tại nếu đúng thì Spark sẽ raise lỗi ngay vào lúc này, nhưng Spark vẫn sẽ tạo ra một Unresolved Logic Plan/Parsed Logical Plan (Blank Logical plan).
Analyzed Logical Plan
Sau khi Spark tạo ra Unresolved Logical Plan sẽ đi qua componen Catalog. Catalog là nơi chứa các metadata của dataFrame, Spark table, Dataset. Spark sẽ sử dụng những Rule ở Catalyst và Catalog sẽ giúp Spark check những column name, data type để resolve và sẽ tạo ra Logical plan/Analyzed Logical plan.
Optimize Logical Plan
Sau khi Logical plan được tạo ra sẽ qua 1 bước là Logical Optimize, ở bước này Catalyst sẽ optimize lại logical plan của chúng ta.
Ví dụ: mình có 2 Dataframes:
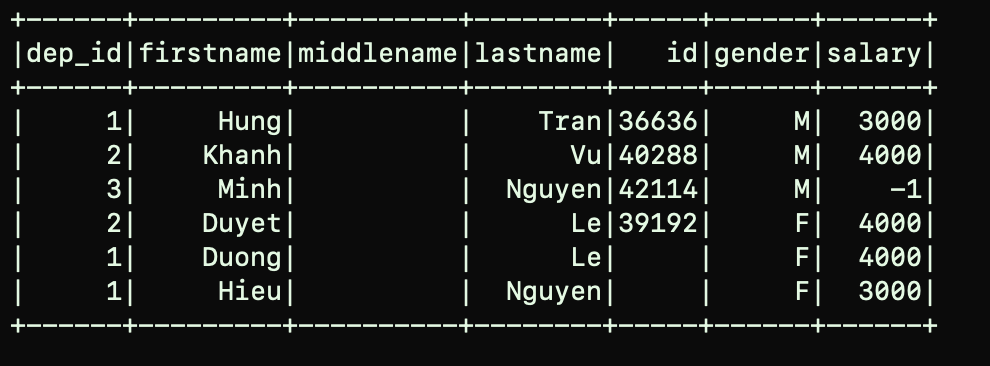

Bây giờ mình sẽ thực hiện các bước transform như sau:
df3 = df1.join(df2, df1.dep_id == df2.dep_id, "inner")
.filter(df1.salary >= 4000)
.withColumn("salary", df1.salary*3)
.filter((df1.firstname == "Duyet") | (df1.firstname == "Duong"))
Đầu tiên mình sẽ join Dataframe lại với nhau. Filter những ai có salary >= 4000, Sau đó nhân 3 giá trị của cột salary ở df1, sau đó filter firstname là Duyet hoặc Duong. Đây sẽ là expected bahavior mà chúng ta muốn. Bây giờ chúng ta sẽ xem Logical plan mà Spark sẽ tạo ra nhé
df3.explain(True)

Như các bạn thấy Unresolved logical plan sẽ không hiển thị các data type của data

Sau khi Analyzed Spark sẽ biết được các data type của các column trên data.
Bây giờ hãy đọc cái plan này nha. Để đọc plan của Spark chúng ta sẽ đọc ngược, đọc từ dưới lên trên. Đầu tiên sẽ là
- Join 2 dataframe
- Filter Salary >= 4000
- Project (Select) các cột đồng thời cột salary * 3
- Bước cuối cùng sẽ filer lại những người có tên là Duyet hoặc Duong
Rõ ràng các bước transform này không tối ưu. Nếu là mình sẽ viết 1 cách tối ưu hơn bằng cách filter trước những điều kiện có sẵn rồi mới join 2 data sau cùng, nhưng đây là ví dụ để thấy được Spark Catalyst sẽ optimize như thế nào. Mình tiếp tục nhìn xem Optimize Logical Plan sau khi Spark Optimize nhé.

Sau khi Optimized chúng ta thấy các step đã được tự động thay đổi và được gộp lại chung với nhau
- Đầu tiên sẽ filter df2 cột dep_id not null
- Tiếp theo sẽ gộp filter Salary >= 4000 và filter firstname và cột dep_id not null cho df1
- Cuối cùng mới join
Rõ ràng là đã Optimize hơn các bước Expect behavior.
Tuy nhiên mình có 1 lưu ý là Catalyst Optimizer chỉ có DataFrame hoặc DataSet hoặc SQL query mới có thể chạy qua 1 số Spark Feature như Catalyst Optimizer hoặc Tungsten Optimizer. Nếu các bạn sử dụng RDD để process các bạn phải tự tối ưu.
Sau khi có Optimize Logical plan, ở Physical planning Spark sẽ generate ra nhiều physical plan. Cost model sẽ tính cost của từng Physical plan sao cho tối ưu nhất và chọn nó, Ngoài ra Cost-base optimization sẽ chọn cách join sao cho phù hợp nhất với data.
Physical plan

Ở physcal plan sẽ có 2 bước:
Bước 1:
Tạo ra những step sử dụng các strategies ứng với mỗi node của logical plan, ví dụ:
- Trong logical plan: JOIN
- Trong Physical plan: SortMergeJoin, BroadcastHashJoin
Bước 2:
Final version plan sẽ được thực hiện, tạo ra RDD code
Operator
- FileScan: miêu tả việc đọc data từ 1 format.
- Exchange: miêu tả việc shuffle - physical data movement trên cluster.
- HashAggregate, SortAggregate, ObjectHashAggregate: Miêu tả data aggregation.
- SortMergeJoin: Miêu tả việc join 2 dataframe, Exchange và sort thường sẽ xảy ra trước khi SortMergeJoin nhưng không nhất thiết phải xảy ra.
- BroadcastHashJoin: Miêu tả việc join 2 dataframe.
Additional Rules
Ngoài Operator còn có những rule như:
- EnsureRequirements
- ReuseExchange
- …
Sau khi chọn ra được Physical plan phù hợp. Code generator sẽ generate Java code Binary và sẽ được thự hiện trên các worker.
Executor
Spark app thường sẽ start 1 hoặc nhiều Executor để thực hiện task.
Mặc định (Static Allocation of Executors) với chế độ này Executor thường sẽ chạy cho tới khi nào Spark app kết thúc. Việc này dẫn đến không tối ưu về resource
Khác với static (Dynamic Allocation). các Executor sẽ tự động remove khi thực hiện xong task. Việc này sẽ tiết kiệm resource cho cluster.
Ngoài ra Executor report hearbeat và các metrics của task về cho driver.
Executor có thể run multiple task song song và tuần tự, và tracking những task đang chạy.
References
https://github.com/JerryLead/SparkInternals
https://www.slideshare.net/databricks/physical-plans-in-spark-sql
https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
https://books.japila.pl/apache-spark-internals/
Spark Submit Conference